Enhancing AI Security and Delivery with Semantic Caching

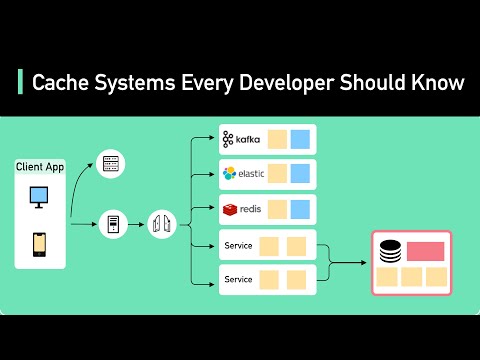
In the realm of artificial intelligence, the utilization of semantic caching has emerged as a powerful tool to bolster security and streamline operational efficiency. Rather than simply relying on traditional traffic routing methods, semantic caching plays a pivotal role in expediting response times and curbing operational costs by eliminating redundant tasks within large language models (LLMs).
This innovative approach transcends mere rate limiting and traffic management, offering a multifaceted solution to combat a spectrum of inbound attacks including prompt injection, model denial-of-service, and sensitive information disclosure. Notably, the AI Gateway’s ability to scrub personally identifiable information (PII) from outbound responses underscores its commitment to data privacy and security.
Moreover, the integration of semantic caching with F5’s NGINX application security suite and BIG-IP application delivery platforms signifies a cohesive strategy to fortify AI systems against evolving threats. By harnessing semantic caching alongside meticulous audit log requirements and content-based model routing, organizations can effectively observe, protect, and accelerate their AI initiatives while ensuring adherence to compliance standards.
In essence, the convergence of semantic caching technology with AI security mechanisms heralds a new chapter in safeguarding data integrity and optimizing operational workflows in the digital landscape.
FAQ Section:
What is semantic caching?
Semantic caching is a technique used in artificial intelligence to improve security and operational efficiency by eliminating redundant tasks within large language models. It plays a key role in expediting response times and reducing operational costs compared to traditional traffic routing methods.
How does semantic caching contribute to security in AI systems?
Semantic caching goes beyond simple traffic management and rate limiting. It helps combat various inbound attacks, such as prompt injection, model denial-of-service, and sensitive information disclosure. The technology, when integrated with AI Gateway, can scrub personally identifiable information (PII) from responses, enhancing data privacy and security.
How does the integration of semantic caching with F5’s NGINX and BIG-IP platforms benefit AI systems?
The integration of semantic caching with F5’s NGINX application security suite and BIG-IP application delivery platforms creates a cohesive strategy to enhance the security of AI systems. This combined approach, along with audit log requirements and content-based model routing, enables organizations to observe, protect, and accelerate their AI initiatives while ensuring compliance with standards.
Key Terms and Definitions:
– Semantic caching: A technique used in AI to eliminate redundant tasks within large language models, improving response times and reducing operational costs.
– Large language models (LLMs): Complex AI models that process and generate human-like language.
– AI Gateway: A component that enhances data privacy and security in AI systems by scrubbing personally identifiable information from outbound responses.
– Personally identifiable information (PII): Data that can be used to identify an individual, such as names, addresses, or social security numbers.
– F5’s NGINX: A popular application security suite that, when integrated with semantic caching, helps fortify AI systems against threats.
Related Links:
– F5 – Visit the main domain for more information on F5’s products and solutions in the realm of cybersecurity and AI.
– NGINX – Explore NGINX’s application security suite and how it can be integrated with semantic caching for AI systems.